


वैज्ञानिक कंप्यूटिंग, संचार और कृत्रिम बुद्धिमत्ता (एससीए) समूह
आईयूएसी में एससीए समूह सक्रिय रूप से कुछ महत्वपूर्ण गतिविधियों में शामिल है ।
इसकी प्राथमिक गतिविधियों में शामिल हैं-
- आईयूएसी में परम रुद्र सुपर कंप्यूटिंग सुविधा
- ऑपरेटिंग सिस्टम और सर्वर प्रबंधन
- भंडारण सर्वर
- स्थानीय क्षेत्र नेटवर्क और इंटरनेट सेवाएं
- वेबसाइट प्रबंधन
- प्रायोगिक भौतिकी और औद्योगिक नियंत्रण प्रणाली (ईपीआईसीएस)
- आईयूएसी एआई/एमएल प्रयोगशाला गतिविधियां: एज एआई, टाईनी एमएल और एआई (सुपर कंप्यूटिंग)
एससीए समूह द्वारा संचालित अन्य गतिविधियों में शामिल हैं-
- अभिगम नियंत्रण प्रणाली
- एकीकृत आईपी संचार प्रणाली
- सीसीटीवी और निगरानी
- ऑडियो वीडियो प्रबंधन
- शैक्षणिक और प्रशासनिक कंप्यूटिंग
आईयूएसी में परम रुद्र सुपर कंप्यूटिंग सुविधा
आईयूएसी उच्च प्रदर्शन कंप्यूटिंग सुविधा शुरू में 2009-2010 में 9 टेराफ्लॉप एमपीआई क्लस्टर के रूप में स्थापित की गई थी । बाद में, वर्ष 2012-2013 में, डीएसटी के वित्तीय समर्थन के साथ समानांतर भंडारण के 55 टीबी के साथ 61 टेराफ्लॉप एमपीआई क्लस्टर की कंप्यूटिंग क्षमता के लिए प्रणाली का विस्तार किया गया था।
वर्ष 2020 में, राष्ट्रीय सुपरकंप्यूटिंग मिशन (एनएसएम) ने आईयूएसी में स्वदेशी रूप से विकसित और निर्मित 3 पेटाफ्लॉप सुपरकंप्यूटिंग क्लस्टर की स्थापना की सिफारिश की । वर्ष 2023-2024 में, क्लस्टर की स्थापना और तैनाती सी-डैक पुणे की सहायता से पूरी की गई थी ।
माननीय प्रधान मंत्री श्री नरेंद्र मोदी ने 26 सितंबर, 2024 को परम रुद्र सुपरकंप्यूटिंग सिस्टम सुविधा राष्ट्र को समर्पित की ।

परम रुद्र डिजाइन

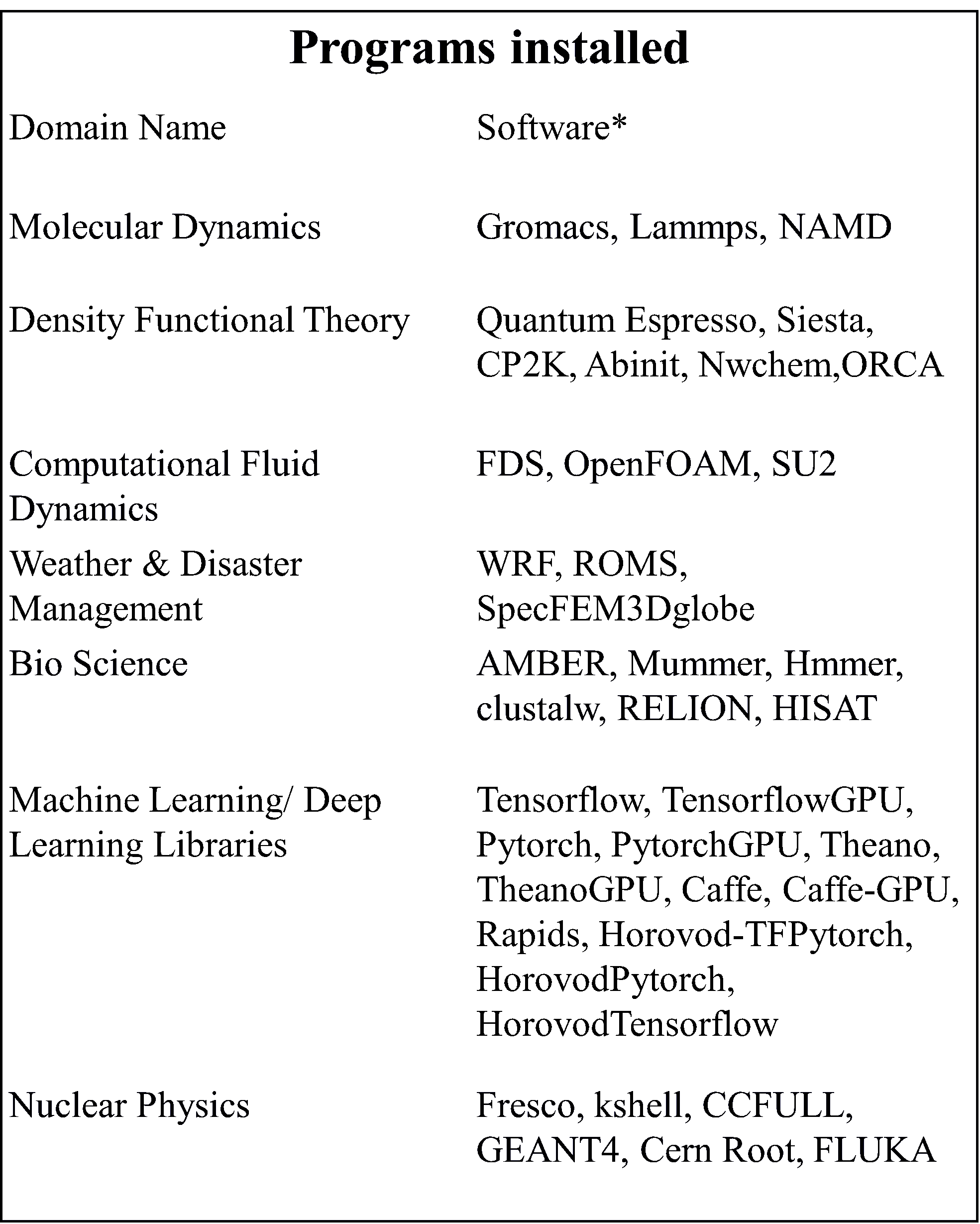

सॉफ्टवेयर स्टैक:
सुपरकंप्यूटिंग क्लस्टर पर खाता कैसे खोलें ?
अपने शोध समस्या विवरण और कारण सहित कंप्यूटिंग संसाधनों की आवश्यकता पर bhuban@iuac.res.in को एक ईमेल लिखें या दिए गए क्यूआर कोड को स्कैन करें ।

ऑपरेटिंग सिस्टम और सर्वर प्रबंधन
एससीए समूह आईयूएसी में ऑपरेटिंग सिस्टम और सॉफ्टवेयर प्रबंधन के सभी पहलुओं के प्रबंधन के लिए जिम्मेदार है । इसमें संगठन भर में ऑपरेटिंग सिस्टम और सॉफ्टवेयर की स्थापना, कॉन्फ़िगरेशन और रखरखाव से संबंधित मुद्दों पर कार्य करना शामिल है । समूह यह सुनिश्चित करता है कि एंटीवायरस कार्यक्रम, एमएस कार्यालय, विंडोज और अन्य आवश्यक अनुप्रयोगों सहित सभी आवश्यक सॉफ़्टवेयर अद्यतन हैं और ठीक से काम कर रहे हैं । ऐसे मामलों में जहां नए सॉफ्टवेयर लाइसेंस की आवश्यकता होती है, एससीए समूह आवश्यक लाइसेंस की खरीद और स्थापना का कार्य संभालता है, कानूनी और परिचालन आवश्यकताओं का अनुपालन सुनिश्चित करता है । उनका सक्रिय दृष्टिकोण सभी सॉफ्टवेयर उपकरणों के सुचारू कामकाज को सुनिश्चित करता है, जिससे संगठन की दक्षता और उत्पादकता बनी रहती है ।
एससीए समूह निम्नलिखित सर्वर का भी प्रबंधन करता है-
क) गेट
गेट सर्वर कई जरूरतों को पूरा करने के लिए स्थापित किया गया था। सर्वर को मूडल नामक ओपन-सोर्स पैकेज का उपयोग करके ओपन ऑनलाइन पाठ्यक्रम बनाने और प्रकाशित करने के लिए एक लर्निंग मैनेजमेंट सिस्टम (एलएमएस) के रूप में कॉन्फ़िगर किया गया है । सर्वर में ‘आईयूएसी फॉर्मस’ पैकेज भी है, जो विभिन्न प्रकार के ऑनलाइन फॉर्म्स की मेजबानी और प्रबंधन के लिए स्वदेशी रूप से डिजाइन, विकसित और प्रबंधित पैकेज है । यह आईयूएसी के भर्ती पैकेज की भी मेजबानी कर रहा है ।
ख) आईडीपी
इन्फ्लिबनेट, गांधीनगर ने इस सर्वर को आईयूएसी कर्मचारियों के लिए, जो आईयूएसी नेटवर्क के बाहर से अनुसंधान लेखों को प्राप्त करना चाहते हैं, शिबोलेथ पहचान प्रदाता के रूप में कार्य करने के लिए कॉन्फ़िगर किया है । पुस्तकालय और कंप्यूटर समूह संयुक्त रूप से आईडीपी सर्वर बनाए रखते हैं ।
ग) सीएसटी
सीएसटी माइक्रोवेव स्टूडियो लाइसेंसिंग सर्वर को आईयूएसी कंप्यूटर समूह द्वारा होस्ट किया जा रहा है । सर्वर IUAC नेटवर्क के भीतर CST स्टूडियो का उपयोग करके ग्राहकों को लाइसेंस प्रदान करता है ।
घ) सोल
पुस्तकालय प्रबंधन हेतु आईयूएसी पुस्तकालय की जरूरतों को पूरा करने के लिए सर्वर स्थापित किया गया था । सर्वर को इन्फ्लिबनेट, गांधीनगर के समर्थन से स्थापित किया गया था और अब इसे आईयूएसी सर्वर पर होस्ट किया गया है । पुस्तक प्रविष्टि और रिकॉर्ड रखने का काम पुस्तकालय द्वारा किया जाता है ।
ड़) एलटीएसपी
एलटीएसपी, जिसका तात्पर्य लिनक्स टर्मिनल सर्वर परियोजना है, थीन क्लाइंटस को नेटबूट करने के लिए स्थापित किया गया था। सर्वर एक ओपन-सोर्स लिनक्स वितरण चला रहा है और उनकी कंप्यूटिंग आवश्यकताओं का प्रशासन करता है।
भंडारण सर्वर
अंतर-विश्वविद्यालय त्वरक केंद्र (आईयूएसी), एक अनुसंधान-उन्मुख संगठन होने के नाते, वैज्ञानिक प्रयोगों और चल रही प्रयोगशाला परियोजनाओं के माध्यम से बड़ी मात्रा में डेटा उत्पन्न करता है। इसका समर्थन करने के लिए, आईयूएसी ने एक भंडारण प्रणाली लागू की है जो अत्यधिक सुरक्षित, आवश्यक है, और एफटीपी, एसएमबी, एनएफएस जैसे विभिन्न भंडारण प्रोटोकॉल का समर्थन करती है, कुशल और विश्वसनीय डेटा प्रबंधन सुनिश्चित करती है।
स्थानीय क्षेत्र नेटवर्क और इंटरनेट सेवाएं
LAN और इंटरनेट सेवाओं का प्रबंधन कई वायर्ड कोर स्विच, वायर्ड एज स्विच, वायरलेस POE स्विच और कंट्रोलर और वायरलेस एक्सेस पॉइंट के माध्यम से किया जा रहा है। प्राथमिक इंटरनेट सेवाएं राष्ट्रीय ज्ञान नेटवर्क (एनकेएन) द्वारा बैंडविड्थ 1 जीबीपीएस के 1:1 कनेक्शन के साथ प्रदान की जाती हैं। अतिरेक उद्देश्यों के लिए, ईशान वेंडर द्वारा बैंडविड्थ 100 एमबीपीएस का द्वितीयक लिंक प्रदान किया जा रहा है। किसी भी प्रकार से विफलता न हो, इसके लिए हमारे पास HA मोड में दो फायरवॉल चल रहे हैं । 9 इमारतों में फैले वायर्ड नेटवर्क के ट्रैफिक एकत्रीकरण का प्रबंधन करने के लिए हमारे पास कोर स्विच है जिसमें प्रति पोर्ट 10 जीबीपीएस और 23 किनारे के स्विच हैं । विशाल वायरलेस नेटवर्क इन्फ्रा का प्रबंधन करने के लिए हमारे पास केंद्र भर में 66 एक्सेस पॉइंट हैं और नेटवर्क सुरक्षा एएए और त्रिज्या सुविधाओं से समृद्ध है।
वेबसाइट प्रबंधन
क) उद्यम संसाधन योजना
ईआरपी प्रणाली समूह, एक आंतरिक रूप से विकसित और प्रबंधित समाधान है, जिसे कार्मिक, वित्त और खाता, भंडारण एवं क्रय और संपत्ति प्रबंधन जैसे कई प्रशासनिक कार्यों को एकीकृत मंच पर रखते हुए डिज़ाइन किया गया है । इस परियोजना का उद्देश्य विभागों में प्रक्रियाओं को सुव्यवस्थित और स्वचालित करके कागज रहित कार्यालय वातावरण को बढ़ावा देना है ।
ख) मानव संसाधन प्रबंधन प्रणाली
मानव संसाधन प्रबंधन प्रणाली (एचआरएमएस) को भी इन-हाउस विकसित किया जा रहा है। इस प्रणाली को विभिन्न मानव संसाधन प्रक्रियाओं को सुव्यवस्थित और स्वचालित करने, परिचालन दक्षता बढ़ाने के लिए डिज़ाइन किया गया है। वर्तमान में, छुट्टी प्रबंधन मॉड्यूल लाइव और पूरी तरह से कार्यात्मक है, जो कर्मचारी अवकाश अनुरोधों की निर्बाध ट्रैकिंग और अनुमोदन की अनुमति देता है। इसके अतिरिक्त, हम नोट और फ़ाइल प्रबंधन जैसी सुविधाओं के साथ सिस्टम को बढ़ा रहे हैं, जो डिजिटल दस्तावेज़ीकरण और आंतरिक संचार की सुविधा प्रदान करेगा, कागज-आधारित प्रक्रियाओं की आवश्यकता को और कम करेगा। जैसे-जैसे एचआरएमएस विकसित होता है, यह मानव संसाधन से संबंधित सभी कार्यों के लिए एक व्यापक, गैर-कागज़ी समाधान के रूप में काम करेगा, ड्राइविंग दक्षता और अधिक टिकाऊ, डिजिटल कार्यस्थल का समर्थन करेगा।
ग) आईयूएसी वेबसाइट
एससीए समूह आईयूएसी वेबसाइट और इसकी सामग्री के प्रबंधन के लिए उत्तरदायी है, यह सुनिश्चित करता है कि यह अद्यतित रहे और संगठन के उद्देश्यों के साथ संरेखित रहे। समूह आवश्यकतानुसार विभिन्न वेब पृष्ठों के निर्माण और रखरखाव को संभालता है, जिसमें इवेंट पेज, निविदा दस्तावेज अपलोड करना, कार्यशाला नोटिस और अन्य महत्वपूर्ण अपडेट शामिल हैं। समूह वेबसाइट को सूचनात्मक और सुलभ रखने के लिए समर्पित है, जो कर्मचारियों और आगंतुकों के लिए एक निर्बाध ऑनलाइन अनुभव प्रदान करता है।
प्रायोगिक भौतिकी और औद्योगिक नियंत्रण प्रणाली (ईपीआईसीएस)
समूह EPICS का उपयोग करके फेल लैब के लिए नियंत्रण प्रणाली विकसित करने में भी शामिल है । इसकी प्रमुख विशेषताओं में प्रयोगात्मक मापदंडों की वास्तविक समय की निगरानी, डेटा का गतिशील दृश्य और प्रयोगात्मक सेटअप का सहज नियंत्रण शामिल है । नियंत्रण प्रणाली के जीयूआई को प्रयोगशाला संचालन की दक्षता बढ़ाने के लिए डिज़ाइन किया गया है, जो शोधकर्ताओं को अधिक आसानी और सटीकता के साथ प्रयोग करने के लिए एक शक्तिशाली उपकरण प्रदान करता है ।
योजनाबद्ध आरेख:

आईयूएसी एआई/एमएल प्रयोगशाला गतिविधियां: एज एआई, टाइनी एमएल और एआई (सुपर कंप्यूटिंग)
विश्वविद्यालय अनुदान आयोग (यूजीसी) और शिक्षा मंत्रालय (एमओई), भारत सरकार द्वारा स्थापित एक प्रमुख राष्ट्रीय त्वरक प्रयोगशाला, अंतर-विश्वविद्यालय त्वरक केंद्र (आईयूएसी), नई दिल्ली, त्वरक विज्ञान और अत्याधुनिक प्रौद्योगिकियों जैसे आर्टिफिशियल इंटेलिजेंस (एआई) और यंत्र शिक्षण /मशीन लर्निंग (एमएल) की राह पर अनुसंधान को आगे बढ़ाने के लिए प्रतिबद्ध है। विज्ञान और इंजीनियरिंग के विभिन्न क्षेत्रों में एआई और एमएल के बढ़ते प्रभाव के साथ, आईयूएसी एआई/एमएल लैब का उद्देश्य कण त्वरक के क्षेत्र में, एक ऐसा क्षेत्र जो अपेक्षाकृत अज्ञात रहता है , इन प्रौद्योगिकियों की क्षमता का पता लगाना और उनका दोहन करना है । प्रयोगशाला युवा वैज्ञानिकों, इंजीनियरों, शोधकर्ताओं और पीएचडी छात्रों को एज एआई, छोटे एमएल, आरएनएन/एलएसटीएम आधारित समय श्रृंखला सेंसर पूर्वानुमान, विसंगति का पता लगाने, त्वरक नियंत्रण, रखरखाव, सुरक्षा, उपकरणों और अनुकूलन के क्षेत्रों में आईओटी और एआई और एमएल के अनुप्रयोगों में शामिल करने के लिए प्रेरित और संलग्न करना चाहती है । एआई और एमएल ने उद्योगों में डेटा विश्लेषण, पूर्वानुमानित रखरखाव और अनुकूलन तकनीकों में क्रांति ला दी है, और त्वरक विज्ञान में उनका एकीकरण परिवर्तनकारी प्रगति लाने के लिए तैयार है । प्रयोगशाला उन्नत कम्प्यूटेशनल समाधानों के लिए जीपीयू क्षमताओं के साथ उच्च-प्रदर्शन कंप्यूटिंग (एचपीसी) का लाभ उठाकर जटिल विज्ञान और इंजीनियरिंग समस्याओं को हल करने के लिए एआई और एमएल को लागू करने पर ध्यान केंद्रित करती है । नवाचार को बढ़ावा देने के लक्ष्य के साथ, प्रयोगशाला त्वरक प्रौद्योगिकियों के लिए एआई और एमएल में भविष्य की दिशाओं और विकास पर सहयोगी अनुसंधान, प्रशिक्षण और ज्ञान आदान-प्रदान के लिए एक मंच भी प्रदान करती है।
एकीकृत आईपी संचार प्रणाली
यह प्रणाली पारंपरिक और आधुनिक आईपी-आधारित दोनों समाधानों का समर्थन करती है, जो सभी स्टाफ सदस्यों के लिए मजबूत संचार सुनिश्चित करती है।
ऑडियो वीडियो प्रबंधन
अंतर-विश्वविद्यालय त्वरक केंद्र (आईयूएसी) परिसर विभिन्न शैक्षणिक और सांस्कृतिक कार्यक्रमों का समर्थन करने के लिए उन्नत ऑडियो और वीडियो सिस्टम से सुसज्जित है। मुख्य सभागार परिसर में 300 से अधिक सीटर ऑडिटोरियम, 50 से अधिक सीटर सेमिनार हॉल, दो ग्रीन रूम और दो स्तरीय लॉबी शामिल हैं। इसके अतिरिक्त, मुख्य प्रयोगशाला भवन में 40 सीटों वाला पीएचडी क्लासरूम, 90+ सीटर सेमिनार हॉल, एक परिषद कक्ष, एक समिति कक्ष और एक लॉबी क्षेत्र है।
ये सुविधाएं पाठ्यक्रमों, कार्यशालाओं, सम्मेलनों और संगोष्ठियों का समर्थन करने के लिए ऑडियो, वीडियो और संबंधित इलेक्ट्रॉनिक, विद्युत और यांत्रिक प्रणालियों की एक श्रृंखला से सुसज्जित हैं।
समूह उपरोक्त स्थानों पर आयोजित विभिन्न कार्यशालाओं/घटनाओं के लिए आंतरिक स्टाफ सदस्यों द्वारा आवश्यक ऑडियो वीडियो तकनीकी सहायता के अनुरोध का प्रबंधन करता है।
इसके अलावा, हमारे पास बाहरी इच्छुक पक्षों के लिए IUAC ऑडिटोरियम बुक करने का प्रावधान भी है। (फॉर्म आईयूएसी की वेबसाइट पर उपलब्ध है)।
शैक्षणिक और प्रशासनिक कंप्यूटिंग
यह समूह प्रशासनिक कंप्यूटिंग के लिए कई केंद्रीय सर्वर, एलटीएस टर्मिनल, पीसी, प्रिंटर और कार्य स्टेशनों का प्रबंधन करता है।
इसके अलावा, समूह एयूसी मॉड्यूल, भर्ती पोर्टल और आईआरडीसी वेबसाइट के लिए डिजाइन, विकास और रखरखाव गतिविधियों का भी प्रबंधन करता है।
समूह के सदस्य

डॉ. भुबन कुमार साहू
वैज्ञानिक-एच
Ext:333

डॉ. जॉबी एंटनी
अभियंता-जी
Ext:8631

मि. अभिषेक कुमार
वैज्ञानिक-डी
Ext:8213

मि. आनंद प्रकाश
अभियंता-सी
anand.prakash [at] iuac.res.in
Ext:8212

मि. यतेश डबास
अभियंता-सी
Ext:8212

कुमारी. श्वेता अग्रवाल
अभियंता-सी
shweta.agarwal [at] iuac.res.in
Ext:8212

डॉ. मुकेश जाखड़
अनुसंधान सहयोगी

डॉ. निशा गुप्ता
अनुसंधान सहयोगी
अद्यतन की तिथि 28/01/2025
वैज्ञानिक कंप्यूटिंग, संचार और कृत्रिम बुद्धिमत्ता (एससीए) समूह फोटो गैलरी


